Could not create TensorFlow Graph: Invalid argument: No OpKernel was registered to support Op 'DecodeJpeg' with these attrs. Registered devices: [CPU], Registered kernels: <no registered kernels>
# Load the TF graph definition tf_model_path = './tensorflow_inception_graph.pb' with open(tf_model_path, 'rb') as f: serialized = f.read() tf.reset_default_graph() original_gdef = tf.GraphDef() original_gdef.ParseFromString(serialized)
# For demonstration purpose we show the first 15 ops the TF model with tf.Graph().as_default() as g: tf.import_graph_def(original_gdef, name='') ops = g.get_operations() for i in range(15): print('op id {} : op name: {}, op type: "{}"'.format(str(i),ops[i].name, ops[i].type)); >>> op id 0 : op name: DecodeJpeg/contents, op type: "Const" op id 1 : op name: DecodeJpeg, op type: "DecodeJpeg" op id 2 : op name: Cast, op type: "Cast" op id 3 : op name: ExpandDims/dim, op type: "Const" op id 4 : op name: ExpandDims, op type: "ExpandDims" op id 5 : op name: ResizeBilinear/size, op type: "Const" op id 6 : op name: ResizeBilinear, op type: "ResizeBilinear" op id 7 : op name: Sub/y, op type: "Const" op id 8 : op name: Sub, op type: "Sub" op id 9 : op name: Mul/y, op type: "Const" op id 10 : op name: Mul, op type: "Mul" op id 11 : op name: conv/conv2d_params, op type: "Const" op id 12 : op name: conv/Conv2D, op type: "Conv2D" op id 13 : op name: conv/batchnorm/beta, op type: "Const" op id 14 : op name: conv/batchnorm/gamma, op type: "Const"
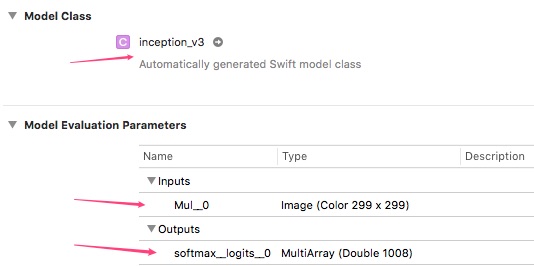
看输出结果可以发现, 原始模型的输入是一个 jpeg 的contents, 开始对其进行了预处理. 这里作者直接把预处理去掉了, 把入口直接设置在了 op id 9这个位置, 即Mul操作
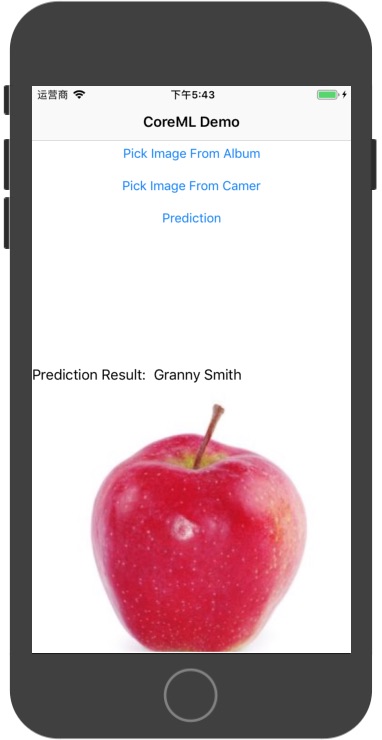
let image = loadImage() let myModel = inception_v3() var pixelBuffer = converToBuffer(image) let result: inception_v3Output = try myModel.prediction(Mul__0: pixelBuffer!) as inception_v3Output
// result 就是输出结果
varmin: Float = 0 var index = -1
for i in0..<result.softmax__logits__0.count { if result.softmax__logits__0[i].floatValue > min { min = result.softmax__logits__0[i].floatValue index = i } } print("result.softmax__logits__0.count=", result.softmax__logits__0.count) // index 即为所在标签的位置 print("index=", index)